시각적으로 볼 때, 리스트, 스택, 큐 등의 추상 자료형이 데이터를 한 줄로 나열한 선형구조(Linear Structure)라면, 추상 자료형 트리는 데이터를 여러 줄로 나열했다는 점에서 비선형 구조(Non-Linear Structure)다. 이러한 비선형 구조를 사용하는 가장 큰 이유는 탐색 시간을 단축하는 데 있다.
트리 (Tree)
계층적인 관계(Hierarchical Relationship)를 나타내는 데 편리한 것. ex) 족보, 기업의 조직도, 컴퓨터 디렉터리 ...
결정 트리(Decision Tree) : 어떤 결정 과정을 나타낸 트리
용어 정리

- 노드(Node) : 트리의 구성 요소(Element)에 해당하는 A, B, C, ... L
- 자식 노드(Child Node) : B의 바로 아래 있는 E, F
- 부모 노드(Parent Node) : E, F의 부모 노드인 B
- 자매 노드(Sibling Node) : 같은 부모 아래에서의 자식 노드들 (B, C, D / E, F)
- 조상 노드(Ancestor Node) : 주어진 노드의 상위에 있는 노드들 (B, A는 F의 조상 노드)
- 후손 노드(Descendant Node) : 어떤 노드의 하위에 있는 노드 (B, E, F, C... 는 A의 후손 노드)
- 루트 노드(Root Node) : A처럼 부모가 없는 노드
- 리프 노드(Leaf Node) / 터미널 / 단말 / 종단 노드 : 자식이 없는 노드
- 내부 노드(Internal Node) : 리프 노드를 제외한 모든 노드
일반 트리(General Tree) : 위와 같이 둘 이상의 자식노드를 가질 수 있는 트리
이진 트리(Binary Tree) : 최대 두 개까지의 자식 노드를 가질 수 있는 트리
하위 트리(Subtree, 부분트리) : 주어진 트리의 부분집합을 이루는 트리. 임의의 노드와 그 노드에 달린 모든 후손 노드를 합한 것. 주어진 트리에는 여러 개의 하위 트리가 존재할 수 있다.
모든 일반 트리는 이진 트리로 바꾸어 표현할 수 있다.
이진 트리의 정의
- 아무런 노드가 없거나,
- 가운데 노드를 중심으로 좌우로 나누어지되, 좌우 하위트리 모두 이진 트리여야 한다.
(공집합-Empty Set은 모든 집합의 부분 집합이므로 아무런 노드가 없는 트리도 주어진 트리의 부분 트리로 간주할 수 있다.)
이같은 이진트리의 정의는 명백히 재귀적이다. 이진트리를 정의함에 있어서 이진트리라는 용어를 사용하고 있는 것이다. 빈 하위트리가 재귀호출의 베이스 케이스에 해당한다. 이진트리의 정의 자체가 재귀적이기 때문에 이진트리에 가해지는 모든 작업은 재귀호출 형태를 띨 수 밖에 없다.
트리의 레벨(Level)은 루트노드를 레벨 0으로 하고 아래로 내려오면서 증가한다.
트리의 높이(Height)는 트리 내의 최대 레벨과 일치한다. 루트노드로부터 가장 먼 리프노드까지 가는 데 필요한 연결(Link) 개수를 말한다.
트리의 정의처럼 트리의 높이 역시 재귀적으로 정의할 수 있다.
트리의 높이 = 1 + Max(왼쪽 하위트리의 높이, 오른쪽 하위트리의 높이)
루트노드 하나만 있는 트리의 높이는 0, 빈 트리의 높이는 -1로 정의된다.
포화 이진트리(Full Binary Tree)
높이 h인 이진트리에서 모든 리프노드가 레벨 h에 있는 트리. 리프노드 위쪽의 모든 노드는 반드시 자식노드 두 개를 거느리고 있어야 한다. 또 모든 노드에 있어서 왼쪽 자식의 높이가 오른쪽 자식의 높이와 같아야 한다.
노드 개수 : 2^h+1 - 1 (1, 3, 5, 7, 15, 31 ... )

완전 이진트리(Complete Binary Tree)
레벨 (h-1)까지는 포화 이진트리고, 마지막 레벨 h에서 왼쪽에서 오른쪽으로 가며 리프노드를 채운 것. 만약 하나라도 건너뛰고 채운다면 완전 이진트리가 아니다.

어떤 트리가 포화 이진트리라면 이는 완전 이진트리지만, 완전 이진트리라고 반드시 포화 이진트리일 수는 없다.
균형 트리(Height Balanced Tree)
트리의 균형(Balance)이란 루트노드를 기준으로 왼쪽 하위트리와 오른쪽 하위트리 사이의 높이 차이를 말한다. 그 차이가 1 이하일 때 그 트리를 균형트리라고 한다. 위의 완전 이진트리의 예로 나온 그림 또한 루트를 기준으로 왼쪽 하위트리의 높이가 2, 오른쪽 하위트리의 높이가 1이므로 균형트리라 할 수 있다.
완전 균형 트리(Completely Height-Balanced Tree)
왼쪽, 오른쪽 하위트리 높이가 완전히 일치하는 트리.
배열에 의한 이진트리 구현
배열에 의한 트리 구현은 거의 사용되지 않는다. 한 가지 예외가 있는데, 바로 완전 이진트리이다. 이 경우에는 부모 노드를 찾는 작업, 자식 노드를 찾는 작업이 간단한 인덱스 계산만으로 가능하기 때문이다.
완전 이진트리를 배열로 나타낼 때에는 루트로부터 내려오면서 왼쪽에서 오른쪽으로 인덱스를 매긴다. 여기서 부모 노드와 자식 노드의 인덱스 사이에는 다음과 같은 규칙이 존재한다.
- 인덱스 K에 있는 노드의 왼쪽 자식은 (2K + 1)에, 오른쪽 자식은 (2K + 2)에 있다.
- 인덱스 K에 있는 노드의 부모 노드는 (K - 1) / 2 에 있다.
이는 완전 이진트리를 정의할 때 왼쪽에서 오른쪽 순서로 빠짐없이 노드를 채우도록 정의했기 때문에 가능하다. 이처럼 간단한 인덱스 계산만으로 부모노드/자식노드의 위치를 빠른 속도로 찾아갈 수 있기 때문에 완전 이진트리의 구현에는 포인터보다는 배열을 사용하는 것이 훨씬 유리하다.
포인터에 의한 이진트리 구현
이진 트리에서는 왼쪽 자식노드를 가리키는 포인터, 오른쪽 자식노드를 가리키는 포인터 이렇게 두 개가 필요하다. 이진트리의 작업 중 가장 중요한 것이 순회(Traversal)인데, 트리 자체가 재귀적으로 정의되었기 때문에 트리의 순회 역시 재귀적이다.
여기서 루트 노드에 대한 작업이 어디에 위치하느냐에 따라 전위순회, 중위순회, 후위순회로 나뉜다.
- 전위 순회(Pre-order Traversal) : Root -> Left -> Right
- 중위 순회(In-order Traversal) : Left -> Root -> Right
- 후위 순회(Post-order Traversal) : Left -> Right -> Root
전위 순회 코드의 예는 다음과 같다.
void PreOrder(Nptr T) {
if (T != NULL) {
Visit(T->Name);
PreOrder(T->LChild);
PreOrder(T->RChild);
}
}
T 값이 널이라면 더 이상 작업할 것이 없다. 비어 있는 트리가 넘겨졌거나 재귀호출에 의해 리프노드 아래로 내려갔기 때문이다. 재귀호출 부분은 현재 하위트리의 루트에 필요한 작업을 실행한 다음 왼쪽 하위트리에 대해 재귀호출을 하고, 이후에 오른쪽 하위트리에 대해 재귀호출을 하라는 것이다. 중위 순회와 후위 순회도 똑같은 구조이나 순서만 바뀌었을 뿐이다.
트리도 일종의 그래프다. 그래프 순회의 관점에서 트리의 순회 알고리즘을 바라보면 전위순회 방식은 깊이우선 탐색에 해당한다. 루트를 출발점으로 하는 깊이우선 탐색으로써 새로운 노드를 보자마자 우선적으로 그 노드를 먼저 방문하고 이후 거기서 출발하는 다른 노드를 방문한다는 점에서 동일하다.
노드 N개가 있으면 위 세 가지 순회 알고리즘의 효율은 O(N)에 해당한다.
계산 순서가 중요하지 않고 트리 자체의 모든 노드를 빠짐없이 방문하기만 하면 될 때에는 세 가지 순회방식 중 어떤 것을 사용해도 무방하다. 그러나 계산 순서가 중요할 때가 있는데, 전위 순회는 부모 노드에 대한 처리가 선행되어야만 자식 노드가 처리될 수 있을 때에 사용할 수 있고, 후위 순회는 자식 노드에 대한 처리가 완료되어야만 부모 노드가 처리될 수 있을 때에 사용할 수 있다.
전위, 중위, 후위와는 별도로 레벨 순회 (Level-order Traversal)를 정의하기도 한다. 이 순서는 레벨 0에서 1로, 2로, 즉 위에서 아래로, 같은 레벨에서는 왼쪽에서 오른쪽으로 진행한다. 레벨 순회에 해당하는 재귀호출은 존재하지 않는다. 그러나 레벨 순회는 그래프 탐색 방법으로 말하자면 너비우선 탐색에 해당하는 것으로서, 큐 구조를 사용하여 구현할 수 있다.
이진 탐색트리 (Binary Search Tree)
이진트리 중 탐색을 위해 고안된 것. 노드 위치는 키 값을 기준으로 결정된다. 조건은 다음과 같다.
- 노드 N에 대하여 N의 왼쪽 하위트리에 있는 노드는 N보다 작고, N의 오른쪽 하위트리에 있는 노드는 N보다 크다.
- 노드 N에 대하여 N의 왼쪽 하위트리와 N의 오른쪽 하위트리도 전부 이진 탐색트리다.
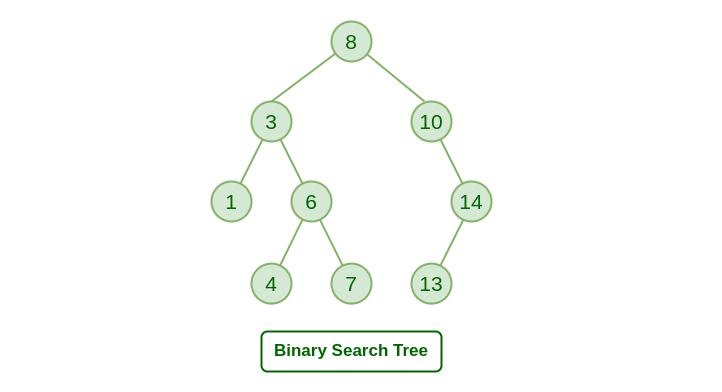
이진 탐색트리는 약하게 정렬되어 있다고 볼 수 있다. 루트를 중심으로 왼쪽 하위트리는 그보다 작은 것, 오른쪽 하위트리는 그보다 큰 것이기 때문이다. 이는 쾌속 정렬의 파티션 개념과 유사하다. 파티션(Partition)이 피벗(Pivot)을 중심으로 작은 것은 모두 왼쪽, 큰 것은 모두 오른쪽으로 몰아넣는 작업이기 때문이다. 이런 의미에서 루트노드는 일종의 피벗에 해당한다고 볼 수 있다.
물론, 왼쪽 하위트리만 놓고 볼 때도 다시 파티션 된 상태다. 즉 하위트리의 루트를 중심으로 다시 그보다 작은 것은 왼쪽, 큰 것은 오른쪽에 존재한다. 이는 쾌속 정렬에서 파티션 된 부분이 또 다른 피벗을 중심으로 재귀적으로 파티션되는 것과 유사하다.
이진 탐색트리의 탐색
탐색 트리를 구성하는 목적은 다름 아닌 탐색에 있다. 코드는 다음과 같다.
Nptr Search(Nptr T, int Key) {
if (T == NULL)
printf("No Such Node"); // 오류 처리 후 빠져나옴
else if(T->Data.Key == Key)
return T; // 찾아낸 노드 포인터를 리턴
else if(T->Data.Key > Key)
return Search(T->LChild, Key); // 값 호출로 전달
else
return Search(T->RChild, Key); // 값 호출로 전달
}
이진 탐색트리의 삽입
모든 삽입은 탐색을 전제로 한다. 삽입도 탐색과 마찬가지로 트리의 루트로부터 시작해서 삽입할 키와 현재 만난 노드의 키를 비교하면서 왼쪽 또는 오른쪽 하위트리를 따라서 내려간다. 마지막에 리프노드를 만났을 때 왼쪽으로 가든 오른쪽으로 가든 모두 널 포인터가 되는데 삽입할 새로운 노드는 바로 이 널 포인터에 연결되어야 한다. 코드는 다음과 같다.
Nptr Insert(Nptr T, int Key) {
if(T == NULL) { // 리프노드의 Child 포인터
T = (node*)malloc(sizeof(node)); // 삽입할 새 노드 만들기
T->Data.Key = Key; // 필요 시 나머지 데이터 필드 복사
T->LChild = NULL; T->RChild = NULL; // 리프노드이므로 자식노드를 널로
}
else if(T->Data.Key > Key)
T->LChild = Insert(T->LChild, Key); // 왼쪽 하위트리로 재귀호출
else
T->RChild = Insert(T->RChild, Key); // 오른쪽 하위트리로 재귀호출
return T; // 현재 하위트리의 루트 포인터
}
이진 탐색트리의 삭제
삭제는 삽입에 비해 조금 까다로운데, 해당 노드의 위치에 따라서 다음 세 가지 경우가 존재하기 때문이다.
- 삭제할 노드가 리프노드인 경우
- 삭제할 노드가 자식노드 하나를 거느린 경우(왼쪽 자식 또는 오른쪽 자식)
- 삭제할 노드가 자식노드 두 개를 거느린 경우
첫째, 삭제할 노드가 리프노드인 경우는 간단하다. 해당 노드의 부모자식의 자식 노드를 널로 놓으면 된다. 예를 들어 위 그림의 예제에서 13을 삭제한다고 할 때 13의 부모 노드인 14의 LChild에 NULL을 대입하면 삭제가 되는 것이다.
둘째, 자식노드 하나를 거느린 경우도 그리 어렵지 않다. 삭제할 노드의 부모 노드가 삭제할 노드의 자식 노드를 가리키면 된다. 14를 삭제하고 싶을 경우 14의 부모 노드인 10의 RChild가 13을 가리키게 하면 되는 것이다. 이렇게 하더라도 이진 탐색트리의 특성은 유지된다. 10, 14, 13 모두 8보다 크기 때문에 8의 오른쪽 하위트리에 존재한다. 따라서 10이 삭제되고 14가 8의 오른쪽 하위트리에 붙어도 이진 탐색트리에서 요구되는 크기 관계는 만족된다.
가장 복잡한 경우가 셋째, 자식이 둘인 경우다. 자식이 둘이라고 해서 부모 노드의 왼쪽이나 오른쪽 자식이 둘을 가리키게 할 수는 없다. 해결책은 다른 노드의 값을 복사한 후 해당 노드는 삭제하는 것이다. 그럼 어떤 값을 복사해야 하는가?
이진 탐색트리를 중위순회(In-order Traversal)하면 정렬된 결과를 낳는데, 예를 들어 위의 예시 트리를 중위순회하면 1, 3, 4, 6, 7, 8, 10, 13, 14가 된다. 크기 면에서 이는 정렬된 순서다. 그렇다면 8이 삭제된 자리에 무엇이 들어가야 하는가. 당연히 8의 바로 오른쪽 10이나 바로 왼쪽 7이 들어가야 한다. 다른 것이 들어가면 정렬이 유지되지 않는다. 8 바로 다음 나오는 10을 중위후속자 (In-order Successor)라 하고, 8 직전에 나오는 7을 중위선행자 (In-order Predecessor)라고 한다. 따라서 삭제될 노드 위치로 복사되어야 하는 것은 중위후속자 또는 중위선행자다. 시각적으로 말하면 삭제하고자 하는 해당 노드의 오른쪽 자식으로 가서, 거기서부터 왼쪽 자식이 있는 한 이를 계속 따라간다. 더 이상 왼쪽 자식이 없는 노드, 즉 LChild가 널인 노드가 중위후속자가 된다. 그런데 중위후속자인 10을 8의 위치에 복사하더라도 원래의 10을 그대로 없앨 수는 없다. 10의 오른쪽 자식인 14가 매달려 있기 때문이다. 따라서 10을 삭제하려면 자식이 하나 있는 경우의 삭제 방법을 적용해야 한다. 즉 10의 부모노드에 10의 자식인 14를 연결하면 된다. 중위후속자의 자식은 없거나 하나다. 중위후속자가 되기 위한 조건으로 LChild가 널이어야만 하기 때문이다.
이진 탐색트리의 효율
탐색에 관한한 이진 탐색트리의 효율은 비교의 횟수에 좌우된다. 즉 루트로부터 시작하여 원하는 키를 가진 노드가 나올 때까지 아래로 내려오면서 몇 번의 비교가 일어났는지가 효율이 된다. 루트에서부터 리프까지 내려오는 비교 횟수는 대략 트리의 높이와 같다. 따라서 이진 탐색트리가 균형 잡혀 있을수록 높이는 log(n)에 가깝게 되므로 탐색의 효율은 O(log(n))에 가까워진다.
| 최악의 경우 | 평균적 경우 | |||||
| 탐색 | 삽입 | 삭제 | 탐색 | 삽입 | 삭제 | |
| 정렬된 배열 | logN | N | N | logN | N/2 | N/2 |
| 정렬 안 된 연결 리스트 | N | 1 | N | N/2 | 1 | N/2 |
| 이진 탐색트리 | N | N | N | logN | logN | N^1/2 |
삭제 작업이 조금 더 오래 걸리는 이유는 삭제된 노드의 자식노드에 대한 처리 때문이다. 크게 봐서는 세 가지 자료구조 중 이진 탐색트리만이 세 작업 모두에 대해 logN에 가까운 효율을 유지한다.
[참고자료]
C/C++로 배우는 자료구조론
'자료구조' 카테고리의 다른 글
| 덱/데크 (Deque), 우선순위 큐 (Priority Queue) (0) | 2024.03.28 |
|---|---|
| 큐 (Queue) (1) | 2024.03.27 |
| 스택 (Stack) (0) | 2024.03.27 |
| 리스트 (1) | 2024.03.26 |
| 배열, 구조체 (0) | 2024.03.24 |



